Abstract
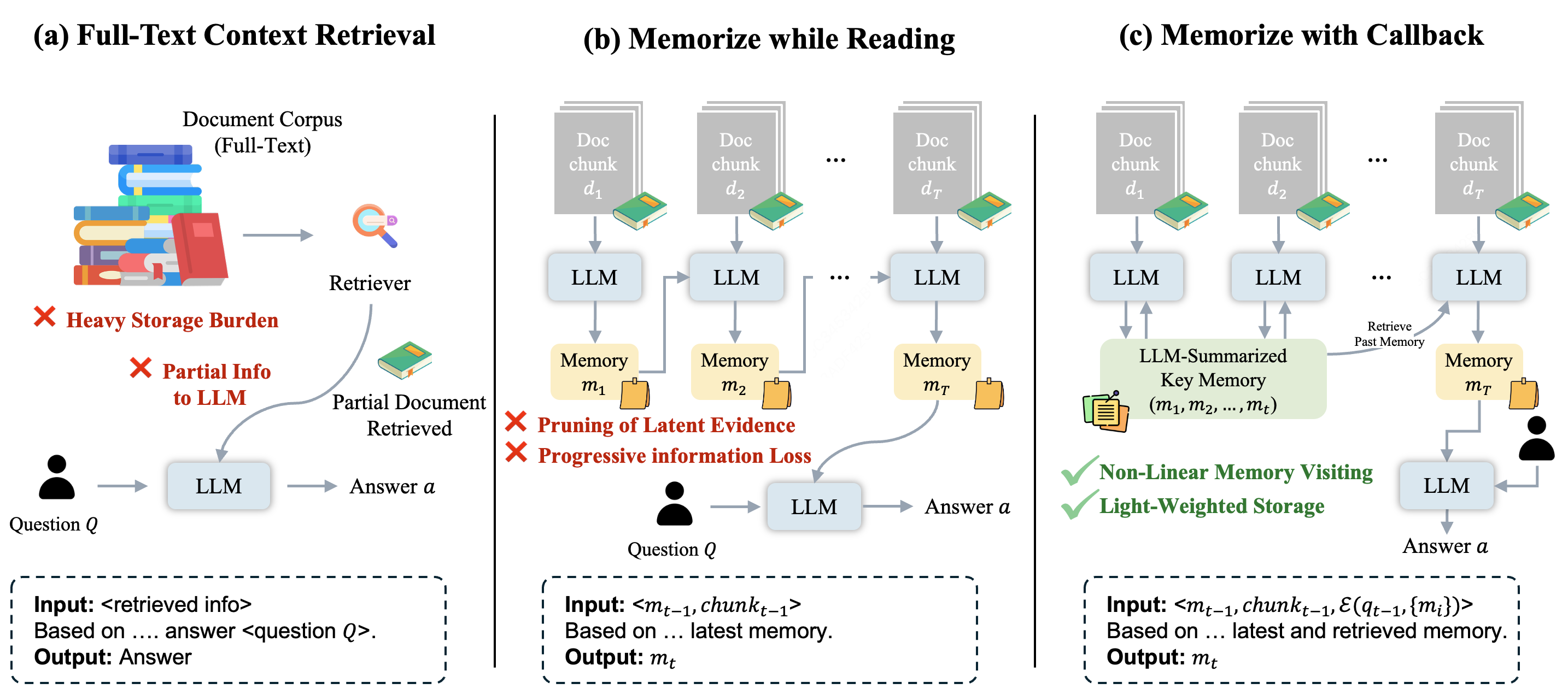
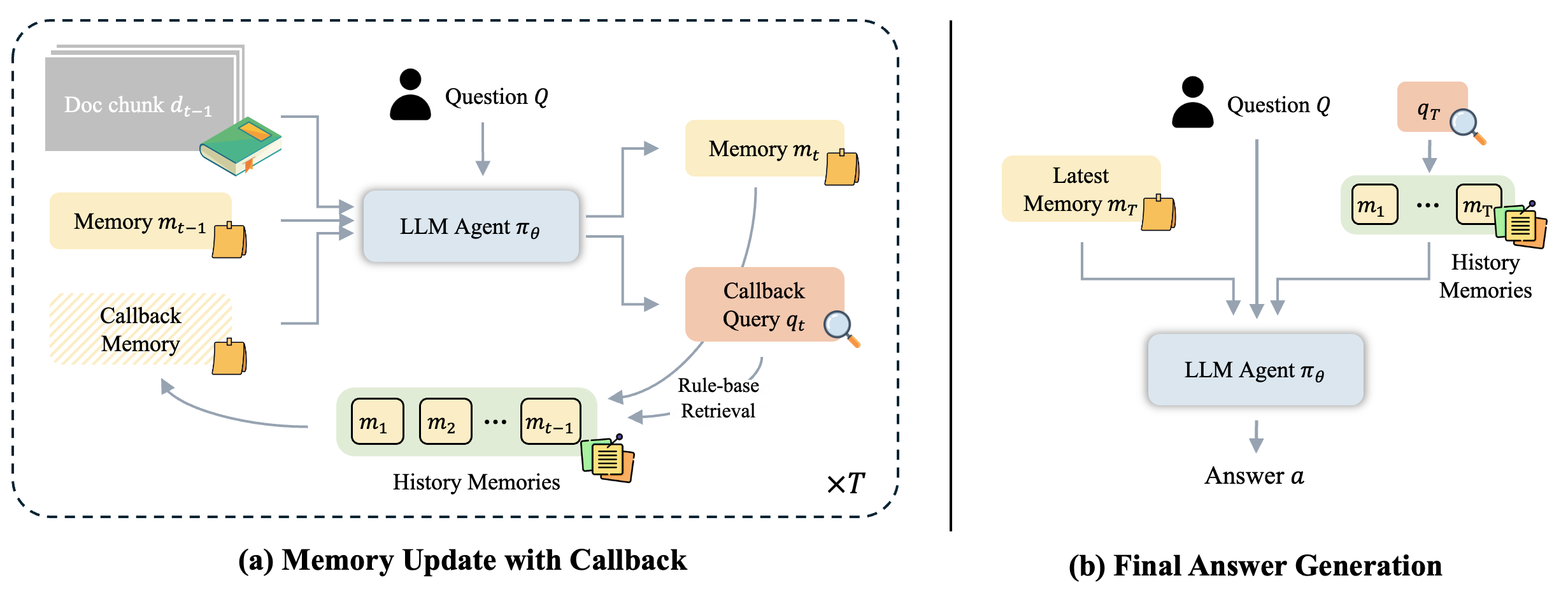
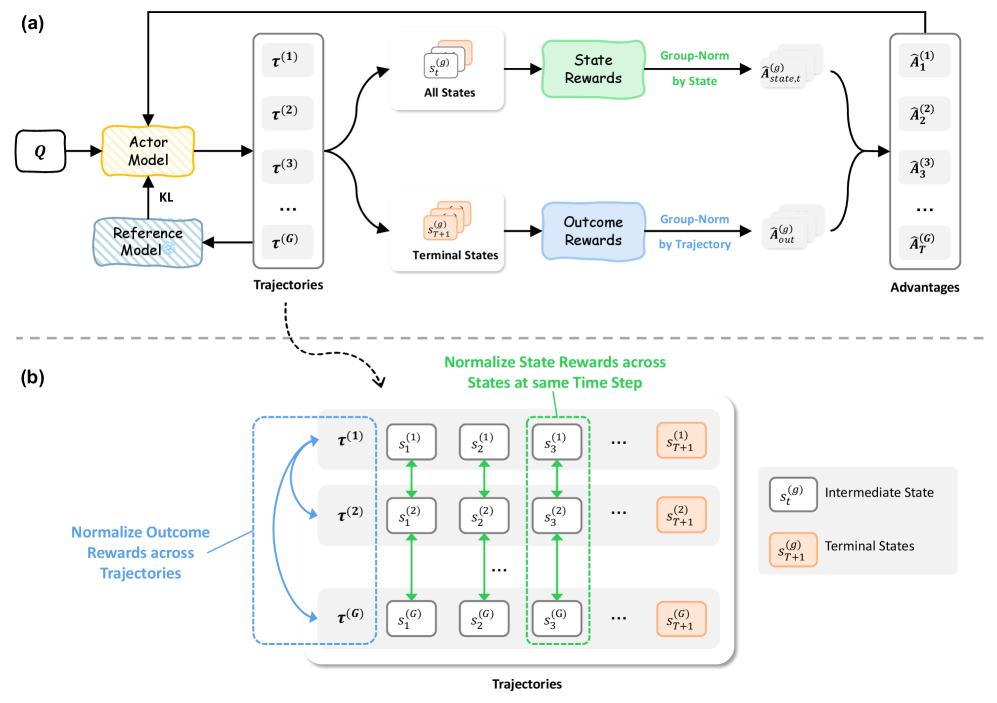
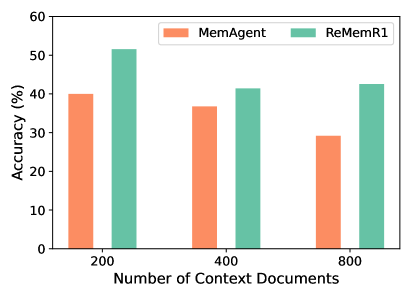
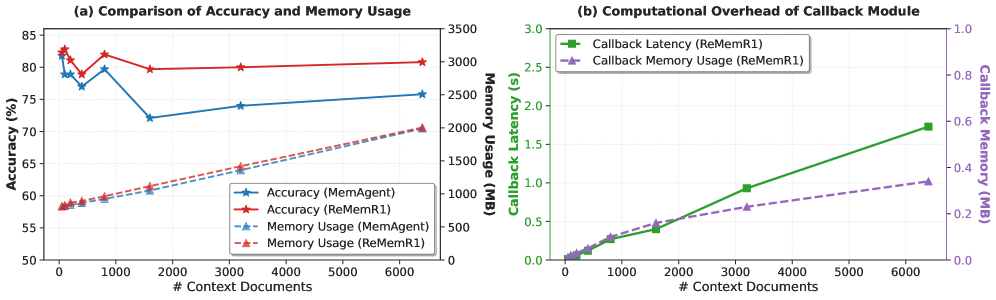
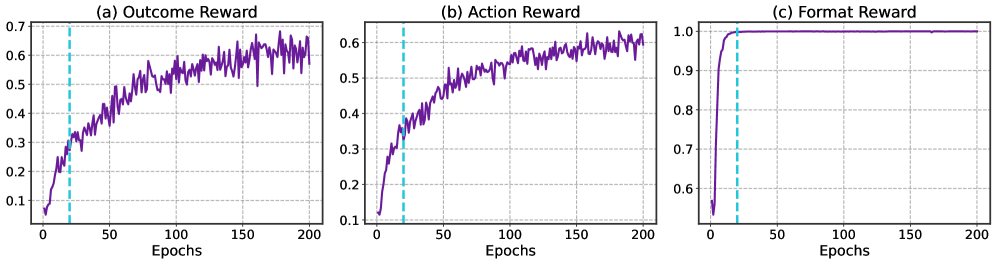
Large language models face challenges in long-context question answering, where key evidence of a query may be dispersed across millions of tokens. Existing works equip large language models with a memory buffer that is dynamically updated via a linear document scan, also known as the "memorize while reading" methods. While this approach scales efficiently, it suffers from pruning of latent evidence, information loss through overwriting, and sparse reinforcement learning signals. To tackle these challenges, we present ReMemR1, which integrates the mechanism of memory retrieval into the memory update process, enabling the agent to selectively callback historical memories for non-linear reasoning. To further strengthen training, we propose a multi-level reward design, which combines final-answer rewards with dense, step-level signals that guide effective memory use. Together, these contributions mitigate information degradation, improve supervision, and support complex multi-hop reasoning. Extensive experiments demonstrate that ReMemR1 significantly outperforms state-of-the-art baselines on long-context question answering while incurring negligible computational overhead.