搜索、精炼、再推理
📖CRGP 结构化分析
大语言模型展现出强大推理能力,但受限于自身知识边界。检索增强推理(RAG)通过查询外部资源来弥补这一不足,但现有方法往往检索到不相关或充满噪声的信息,反而干扰准确推理。如何让模型在推理过程中有效利用外部知识,是当前的核心挑战。
先搜后想:RAG、Self-RAG 等在推理前一次性检索,无法根据推理过程动态调整。
先想后搜:ReAct、IRCoT 等在推理后验证,但错误已经传播。
RL 后训练:Search-o1、R1-Searcher 等引入搜索动作但缺少知识精炼环节。
现有方法的共同盲区:检索到的原始信息直接注入推理链,没有经过过滤和整合。噪声信息在多跳推理中逐步累积,导致推理质量随步数增加而退化。缺少一个在搜索和推理之间的「精炼」环节。
AutoRefine 提出「搜索-精炼-再推理」范式:在连续搜索之间插入显式的 <refine> 步骤,让模型对检索到的证据进行过滤、蒸馏、整合,再将精炼后的知识注入后续推理。配合检索特定奖励的 GRPO 训练,端到端优化搜索行为和推理质量。
01为什么需要 AutoRefine?
大语言模型在推理能力上取得了令人瞩目的进展,但它们的知识本质上是静态的——被「封印」在预训练参数中。这在需要最新信息或长尾事实的任务上构成天然瓶颈。检索增强生成(RAG)是解决这个问题的自然路径:允许模型在推理时访问外部知识库。
然而,现有 RAG 方法存在一个根本性缺陷:它们对检索结果的处理太过被动。以 Search-o1、ReSearch、STILL-3 等代表性方法为例,它们通常的做法是「先想一段,插入搜索,然后继续想」,把检索到的文档片段直接塞入上下文。但现实情况是,搜索引擎返回的结果往往包含大量噪声——不相关的段落、矛盾的信息、甚至误导性内容。将这些「未经处理的原始证据」直接喂给推理链,往往导致模型被噪声干扰,推理质量大幅下降。
更深层的问题在于:多跳推理需要的是知识的累积与整合,而不是单次检索的简单堆叠。当一个问题需要三、四步推理(如「某发明者毕业于哪所大学的哪个院系?」),每一步检索的结果都依赖前几步的推理结论。如果不对中间结果进行整理和精炼,错误会像滚雪球一样在推理链中累积放大。AutoRefine 正是为了打破这个困境而生。
核心矛盾:现有方法只关注「搜到什么」,却忽视了「如何处理搜到的内容」。精炼(Refine)这一步,是 RAG 推理链中长期缺失的关键环节。
02方法详解
AutoRefine 的核心贡献可以拆解为两个相互配合的创新:一是全新的推理范式,二是专为这个范式设计的训练信号。两者缺一不可——范式定义了模型应该做什么,训练信号告诉模型怎样做才算好。
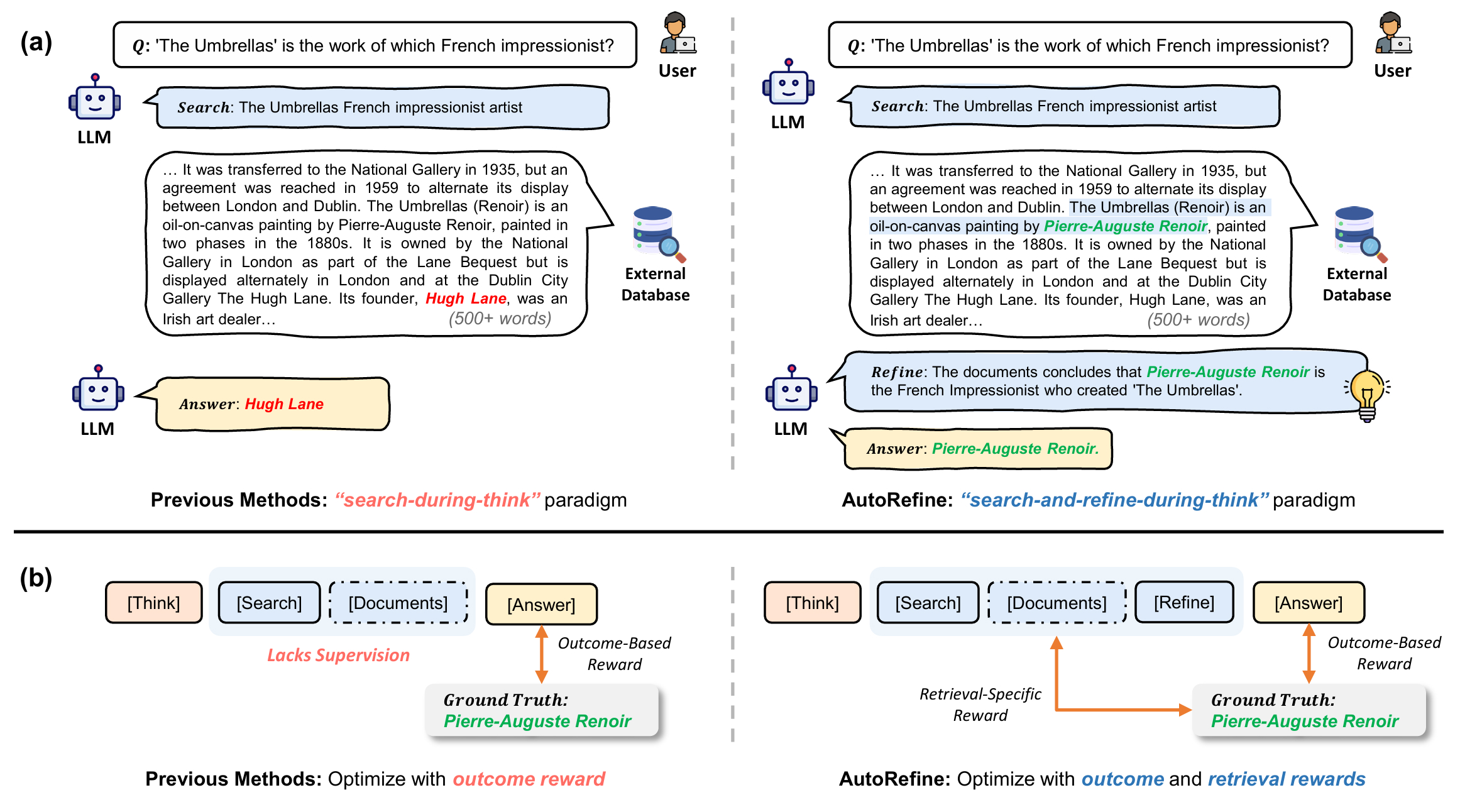
创新一:Search-and-Refine-During-Think 范式
传统「推理时检索」框架遵循固定模式:推理 → 搜索 → 继续推理,将检索到的文档片段原封不动地拼接入上下文。AutoRefine 在两次搜索之间加入了一个显式的「知识精炼」步骤,整个推理流程变为迭代的搜索-精炼循环:
在 <refine> 步骤中,模型被要求对当前已检索到的所有文档进行主动处理:
过滤(Filter)
识别并剔除与当前推理目标无关的文档片段,减少上下文中的噪声密度。这一步尤其重要——搜索引擎往往返回 3~5 个段落,其中只有 1~2 个真正有用。
蒸馏(Distill)
从保留的相关片段中抽取关键事实,以更紧凑的形式重新表述,压缩信息密度。这样后续推理的注意力不会被冗余表述稀释。
整合(Organize)
将多个来源的事实按推理顺序重新组织,形成结构化的知识基础,供后续推理步骤直接调用。类比于研究员读完文献后整理笔记,而不是带着一堆乱序打印稿去写论文。
创新二:检索特定奖励 + GRPO 训练
光有范式还不够——如果只靠 SFT 强制模型输出 <refine> 标签,模型很可能只是机械地「走过场」,精炼内容质量低下。AutoRefine 选择用强化学习(GRPO)来训练,并设计了三种奖励信号协同工作:
使用 Group Relative Policy Optimization(GRPO)是一个关键设计选择。相比 PPO,GRPO 不需要独立的 Critic 网络,通过组内相对排名估计优势函数,训练更稳定、显存更节省——非常适合推理链可能超过 4000 tokens 的长序列生成场景。
一句话概括方法:让 LLM 在推理过程中像一个细心的研究员一样——每搜一次资料,就停下来整理笔记、过滤噪声,而不是把所有资料堆在桌上然后一股脑开始写答案。
03实验结果
AutoRefine 在单跳和多跳 QA 基准上进行全面评估,基座模型为 Qwen2.5-7B-Instruct,与 Search-o1、ReSearch、STILL-3、R1-Searcher 等强基线对比。单跳数据集包括 TriviaQA、PopQA、WebQ;多跳数据集包括 HotpotQA、2WikiMultiHopQA(2Wiki)、MuSiQue。
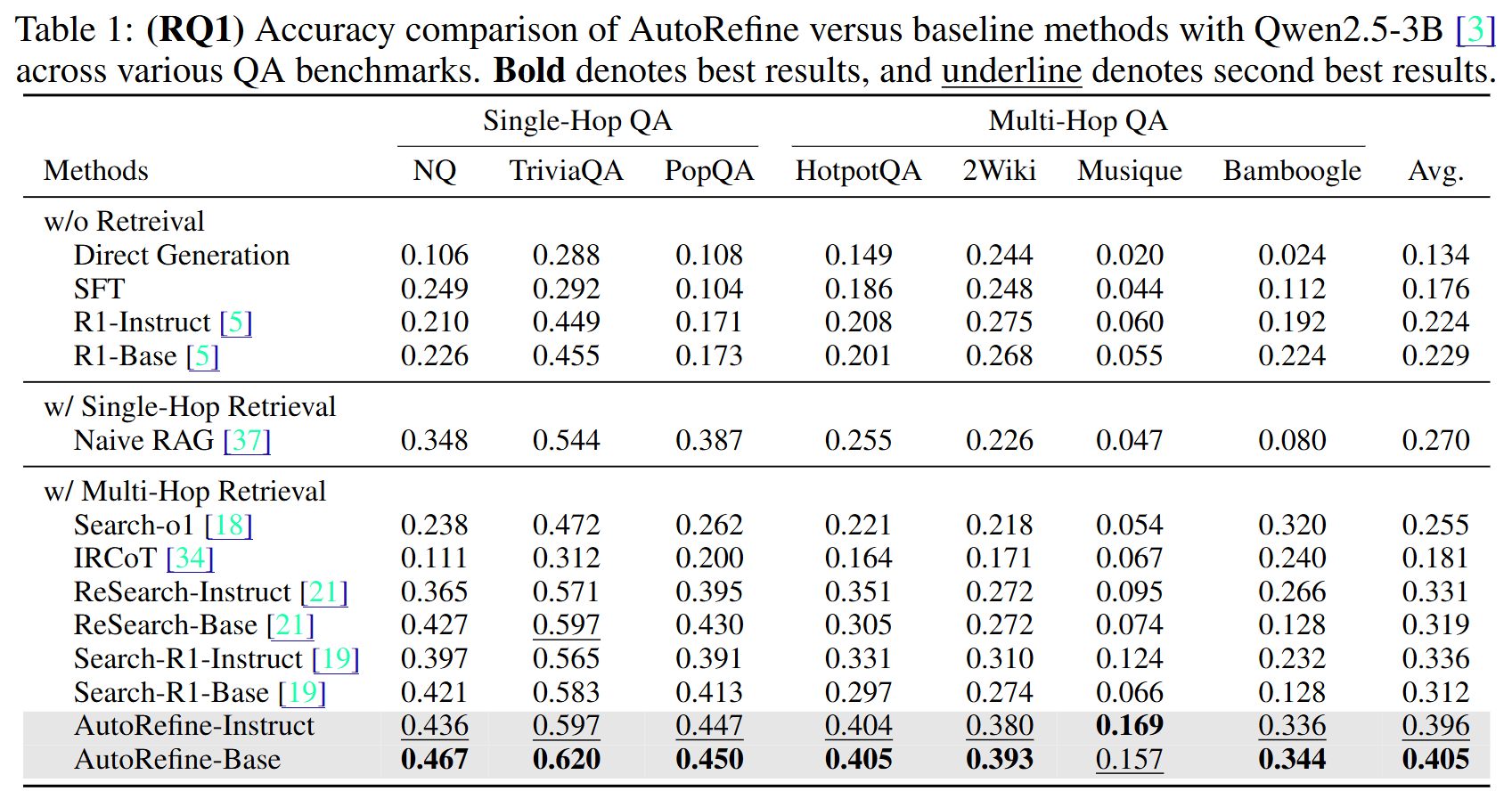
关键数字解读:在 2WikiMultiHopQA 上,AutoRefine 相比 Search-o1 提升显著(具体数值见论文表格);在 MuSiQue(被认为是最难的多跳数据集,需要 4 步以上推理)上,AutoRefine 同样保持领先。单跳数据集上的提升相对温和,这符合预期——精炼步骤在单跳场景的边际收益本就小于多跳。
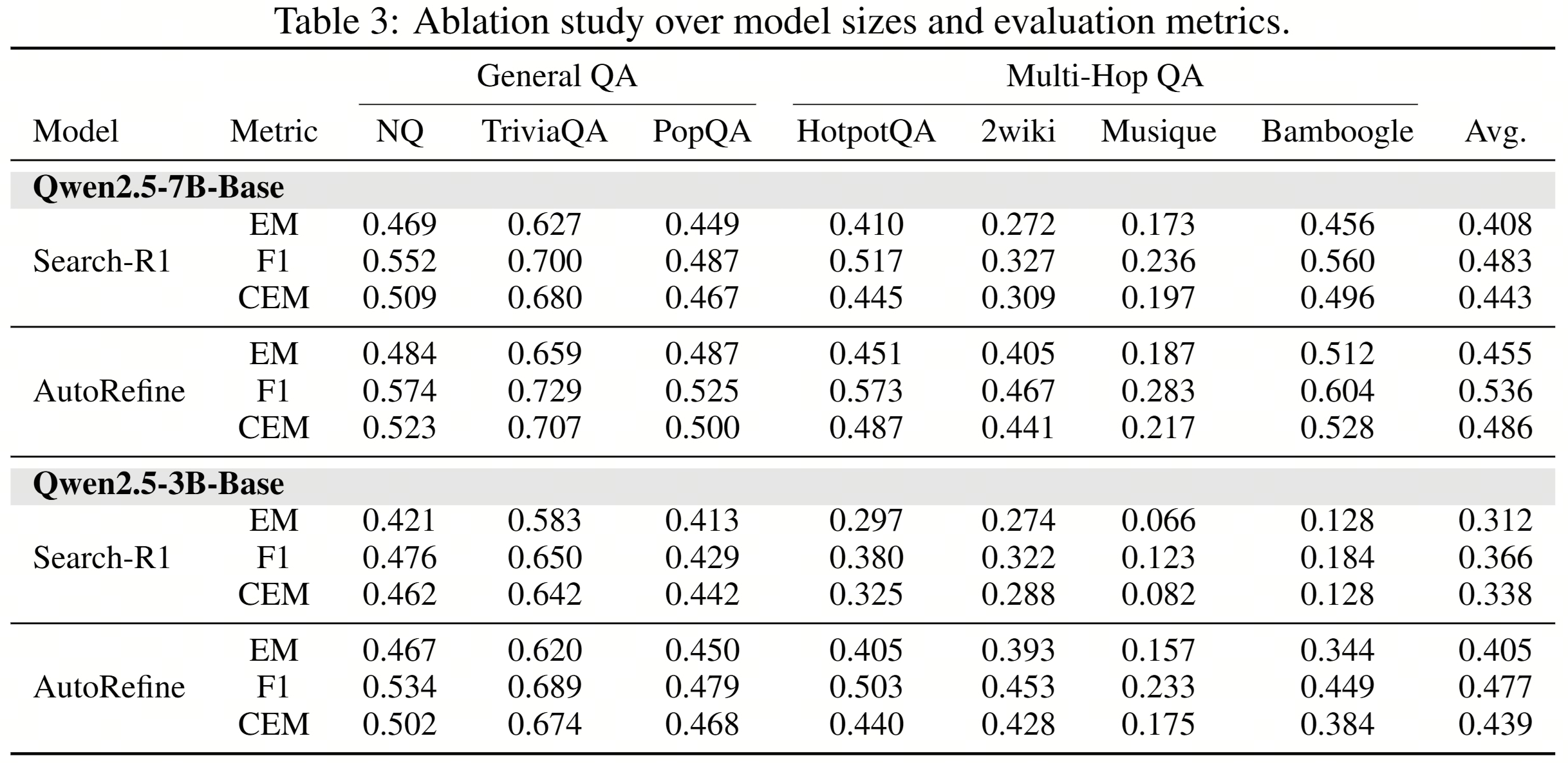
消融实验揭示了各组件的贡献权重:去除 <refine> 步骤后,多跳性能大幅下降,这直接证明了知识精炼的必要性;去除搜索频率奖励后,模型趋向于减少搜索调用;去除搜索质量奖励后,搜索词趋于宽泛、检索噪声增加。三个组件协同才能达到最优效果。
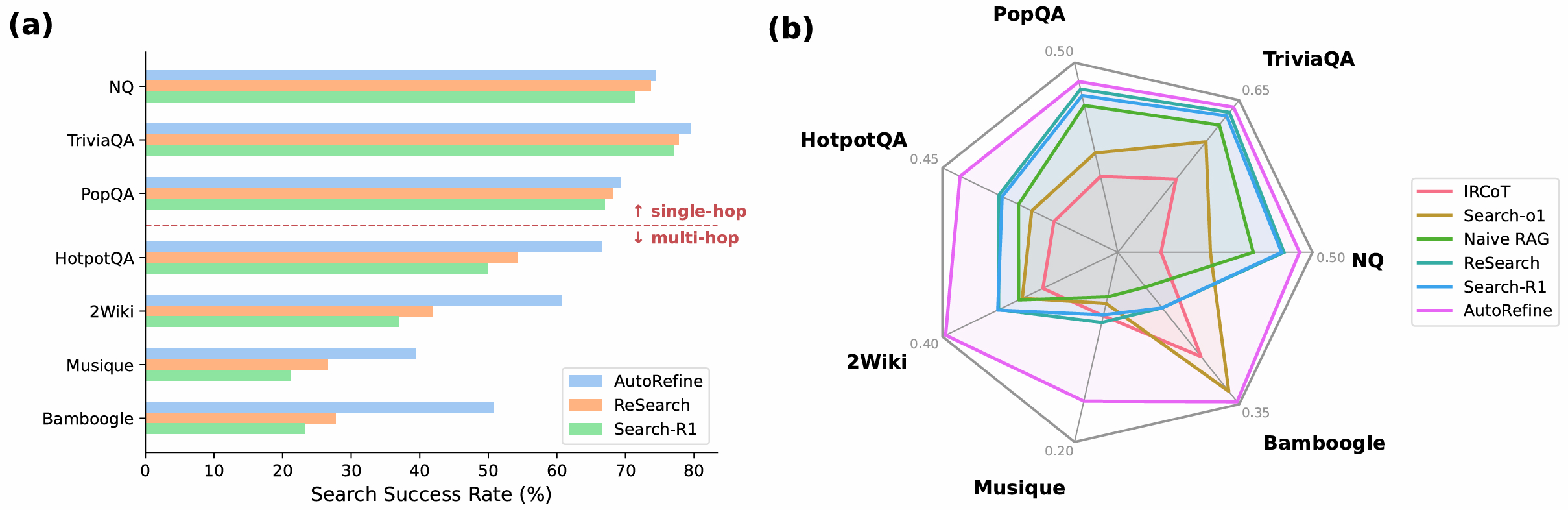
04关键发现与深度分析
超越数字层面,AutoRefine 的实验结果背后有几个值得深思的洞察:
一个有趣的「副产品」发现:经过 GRPO 训练后,AutoRefine 模型在没有检索条件的场景下(即纯参数推理),性能也有所提升。这表明搜索-精炼范式不仅提升了模型的检索利用能力,也在某种程度上强化了其内在推理能力——可能是因为精炼步骤隐式训练了结构化推理和信息整合能力。
05局限性与不足
科学评价需要坦诚的审视。AutoRefine 作为一个 RL 后训练框架,在以下几个方面存在值得注意的局限:
-
推理延迟增加:每次搜索后插入精炼步骤,意味着平均推理链长度显著增加。在对响应速度敏感的场景(如实时问答系统),这是实际部署时必须权衡的代价。精炼步骤本身也消耗 tokens,可能将推理链长度推高 30%~50%。
-
依赖检索系统质量:AutoRefine 的精炼步骤能过滤噪声,但如果检索系统本身质量极差(几乎找不到相关文档),精炼也无能为力。方法的上限被「检索召回率」硬性约束。在特定领域知识库质量参差不齐时,这是重要的 failure mode。
-
单跳场景优势有限:在知识密集型但本质上只需单次检索的问题上,AutoRefine 的增益与计算开销之间的性价比不够理想。方法最适合的场景是需要 3 步以上推理的复杂问题。
-
奖励函数设计的敏感性:三种奖励信号的权重比例对最终性能有影响。论文给出的超参数设置未必是所有场景下的最优配置,在新领域迁移时可能需要重新调整奖励权重。
06核心洞察
从更宏观的视角来看,AutoRefine 代表了一个重要的范式演进方向:将 LLM 从「被动消费检索结果」升级为「主动加工检索结果」。这种主动性不仅提升了当前任务的推理质量,也可能是通往更强「工具使用智能体」的关键一步。
对于后续工作,有几个值得探索的方向:
- 精炼步骤的结构化程度是否可以进一步提升?(如输出知识图谱格式)
- 将精炼能力迁移到更大模型(如 70B)是否能进一步放大优势?
- 检索-精炼范式是否可以扩展到多模态场景(图像+文本检索)?
- 「何时精炼、何时跳过精炼」的自适应决策是否可以进一步优化推理效率?