Agentic Skills Reading List
Structured paper table with figures, benchmarks, and one-line summaries
| Alias | Title | Source | Institution | Benchmarking | ⭐ | Figure | Summary |
|---|---|---|---|---|---|---|---|
| Comp-RL | Complementary Reinforcement Learning | arXiv 2603.17621 | Alibaba Group / HKUST | MiniHack ALFWorld WebShop SWE-Bench | ★★★★★ |  |
受 CLS 启发的 actor-extractor 共演化 RL 框架:静态经验随训练变为负资产,共演化闭环单任务 1.3× margin + 多任务 +7%;split-group GRPO 防止 actor 对经验过度依赖。 |
| ExGRPO | ExGRPO: Learning to Reason from Experience | arXiv 2510.02245 | University of Macau / Shanghai AI Lab | AIME24/25 MATH-500 GPQA★ MMLU-Pro | ★★★★☆ |  |
首个系统研究 RLVR 经验价值的工作:中等难度题+低熵轨迹是最优经验来源;bucketed replay + entropy selection 在 5 模型上平均 +3.5/+7.6(ID/OOD)。 |
| TRT | Test-time Recursive Thinking: Self-Improvement without External Feedback | arXiv 2602.03094 | Microsoft Research | AIME-24/25 LiveCodeBench Hard | ★★★★☆ | N/A | 无需外部反馈的 test-time 迭代自改进:Generate-Select-Reflect 三阶段闭环;开源模型 AIME 100%,核心发现:失败知识 > 成功知识,depth > breadth。 |
| OEL | Online Experiential Learning for Language Models | arXiv 2603.16856 | — | Frozen Lake Sokoban IF-Eval | ★★★★☆ | 经验抽取后再做 on-policy 蒸馏显著优于直接吃原始轨迹(Sokoban consolidate 21.4 vs 7.8),self-policy 经验优于更大教师经验。 | |
| SkillsBench | Benchmarking How Well Agent Skills Work Across Diverse Tasks | arXiv 2602.12670 | — | 86 tasks 11 domains | ★★★★☆ | N/A | 最关键结论:人工 curated skills 平均 +16.2pp,而 self-generated skills 平均退化(-3.3pp pass rate),说明 skill 质量控制比数量更重要。 |
| MemSkill | Learning and Evolving Memory Skills for Self-Evolving Agents | arXiv 2602.02474 | — | LoCoMo LongMemEval HotpotQA ALFWorld | ★★★☆☆ | 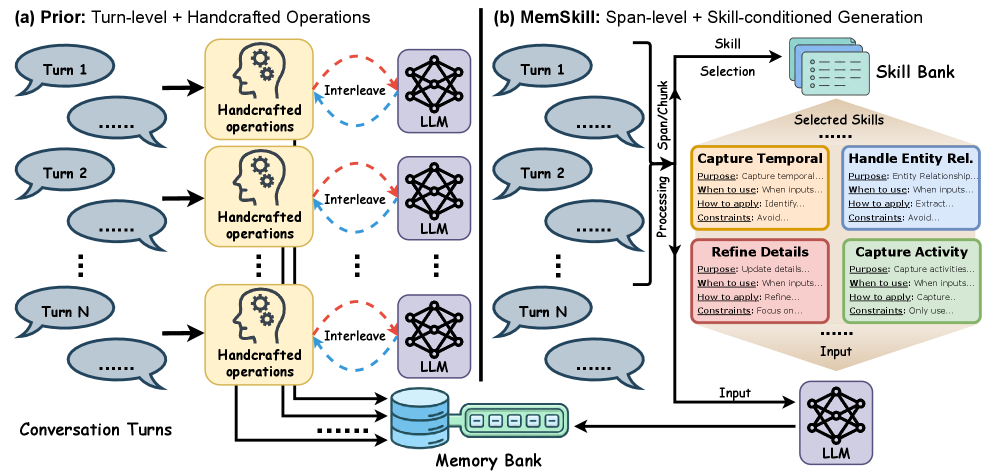 |
把记忆操作做成可检索、可演化 skill(controller/executor/designer);消融显示去掉 designer 退化最大,说明"持续增量技能"是关键。 |
| SkillRL | Evolving Agents via Recursive Skill-Augmented Reinforcement Learning | arXiv 2602.08234 | — | ALFWorld WebShop 7 search tasks | ★★★☆☆ | 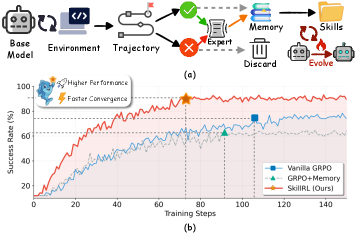 |
轨迹记忆→技能记忆+递归演化有效:复杂子任务增益大、收敛更快,约 10.3% 上下文 token 缩减。 |
| AutoSkill | Experience-Driven Lifelong Learning via Skill Self-Evolution | arXiv 2603.01145 | ECNU / Shanghai AI Lab | Lifelong personalization | ★★★☆☆ |  |
重点不是加检索器,而是把长期经验沉淀为可版本化 SKILL.md 并异步 merge/演化;工程价值在 training-free 个性化闭环。 |
| SkillOrchestra | SkillOrchestra: Learning to Route Agents via Skill Transfer | arXiv 2602.19672 | UW-Madison / Salesforce AI | 10 benchmarks | ★★★☆☆ | N/A | 用"技能需求"而非 query 相似度做路由,能缓解 RL 路由 collapse,在性能-成本 Pareto 上更稳。 |
| SoK-Skills | Agentic Skills — Beyond Tool Use in LLM Agents | arXiv 2602.20867 | — | SoK / taxonomy | ★★★☆☆ |  |
贡献在系统化:给出 skill 四元组与生命周期框架,并把供应链安全纳入同一评估视角。 |
| Survey | Agent Skills for LLMs: Architecture, Acquisition, Security, and the Path Forward | arXiv 2602.12430 | — | Survey | ★★★☆☆ | 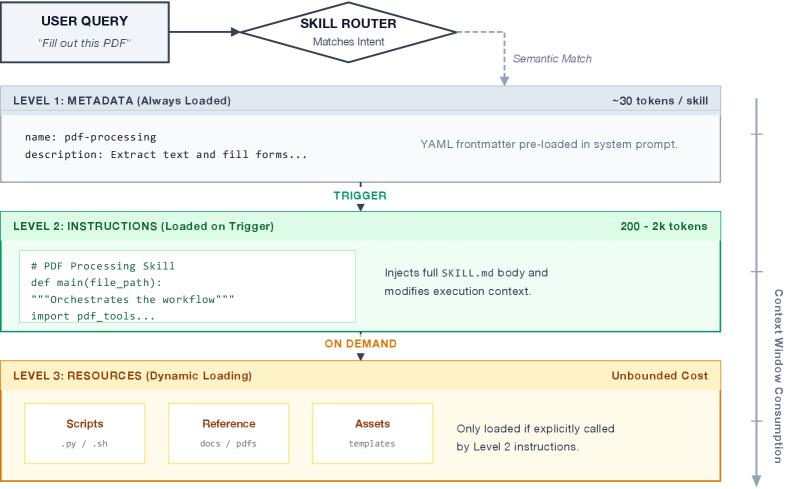 |
价值在于把 architecture/acquisition/security/governance 串成一张图,用大规模安全统计强调 skill 生态的治理刚需。 |